Introduction et définitions
L’informatique évolue vers le traitement de masses d’informations de
plus en plus grandes dans des environnements répartis géographiquement
où doivent cohabiter des matériels hétérogènes.
Dans ce contexte, les bases de données sont utilisées de façon
intensive pour de nombreux domaines d’application tels que le domaine médical,
les administrations ou les associations.
Les applications concernées par l’utilisation d’un SGBD possèdent
des caractéristiques différentes tant au niveau du volume de données
concernées qu’au niveau de la complexité de ces données
et des traitements informatiques à réaliser. Néanmoins,
le regroupement des données dans une base de données gérée
par un système de gestion de base de données apporte de nombreux
avantages dans la plupart des cas d’utilisation. De manière intuitive,
il est possible de définir une base de données de la façon
suivante :
Base de données
Une base de données est une collection de données
sur un domaine d’application particulier où les propriétés
des données ainsi que les relations
sémantiques entre ces données sont spécifiées
en utilisant les concepts proposés par le modèle de données
sous-jacent.
Modèle de données
La notion de modèle de données est essentielle
et c’est elle qui souvent motive le choix de l’utilisation d’une base de données.
En effet, la résolution d’un problème par un
automate nécessite de représenter l’information sur le
domaine traité appelé parfois mini-monde ou univers du discours
sous une forme digitale qui soit interprétable et manipulable par un
ordinateur. Le modèle doit donc être spécifié en
utilisant des données codées et stockées en mémoire
ainsi que par des opérations (programmes) qui déterminent comment
ces données peuvent être utilisées pour résoudre
le problème posé . Un modèle peut se définir comme
une représentation abstraite de l'information et éventuellement
des opérateurs de manipulation de l'information.
Les langages de programmation permettent de définir, stocker et manipuler
des données de façon satisfaisante pour des applications qui adressent
un problème particulier. Cependant, pour des traitements ensemblistes,
ils nécessitent une programmation longue et des tâches répétitives.
Ils manquent de souplesse en cas de modification de structures ou pour l’interrogation
et l’analyse d’un ensemble de données. Ces faiblesses sont dues à
un modèle de données très simple où les traitements
sont définis dans leur intégralité par l’utilisateur.
Le modèle de données offre un niveau d’abstraction supérieur
pour la représentation des données et leurs traitements. La sémantique
additionnelle proposée par le modèle permet de s’abstraire en
fonction du modèle de certains détails liés au stockage
et à la représentation physique des données. Les premiers
modèles utilisés en bases de données, le modèle
hiérarchique et le modèle réseau ont introduit des concepts
de liens entre les données. Ces liens possédaient une sémantique
plus riche que les simples pointeurs utilisés
en programmation et étaient gérés pas le système
de gestion de base de données. Ils permettaient de naviguer dans des
structures de type graphe et d’accéder à des groupes de données.
Dans les années 70, le modèle relationnel a permis d’offrir aux
utilisateurs une vue plus simple et plus homogène données grâce
à une vision tabulaire très intuitive et indépendante de
la gestion physique. De plus, des langages assertionnels
basés sur la logique permettaient d’énoncer des requêtes
basées sur le contenu et non l’emplacement de stockage. Les années
90 ont vu l’approche des systèmes de gestion de bases de données
à objets. L’objectif de ces nouveaux systèmes était de
pallier certains manques des SGBD relationnels notamment pour traiter des données
complexes en adoptant une technologie largement utilisée dans de nombreux
domaines de l’informatique. Aujourd’hui chaque technologie trouve sa place dans
le monde industriel en fonction des besoins des applications.
Idéalement une base de données représente un aspect du
monde réel et le modèle doit donc permettre de spécifier
les propriétés de cohérence, d’évolution des données
et des structures, de représentation des exceptions aux règles
générales, des différents profils des utilisateurs. Dans
la pratique, une base de données fournit un niveau intermédiaire
de représentation entre les fichiers et le monde extérieur qui
permet entre autre d’adresser certains de ces problèmes. La spécification
du schéma de données se fait en passant par une étape de
modélisation où un modèle d’un niveau d’abstraction supplémentaire
est utilisé. Il existe différentes méthodes telles que
Merise, OMT ou UML pour atteindre cet objectif. Certaines sont supportées
par un atelier tel que AMC Designor pour Merise ou Rational ROSE pour UML qui
facilite notamment le passage d’une représentation à l’autre.
Certaines propriétés définies dans les modèles
proposés par ces méthodes sont difficilement traduisibles dans
un modèle de base de données tel que le modèle relationnel.
Néanmoins, certains modèles de bases de données, les modèles
sémantiques, réduisent l’écart entre les niveaux d’abstraction.
Le principal écueil à leur développement est la difficulté
de trouver un compromis entre richesse sémantique et simplicité
d’expression en tenant compte des performances.
Système de Gestion de Bases de données
Un système de gestion de bases de données
(SGBD) est une collection de logiciels permettant de créer, de gérer
et d’interroger efficacement une base de données indépendamment
du domaine d’application.
D’un point de vue fonctionnel, les apports escomptés d’un SGBD sont
les suivants :
 Supporter les concepts définis au niveau du modèle
de données.
Supporter les concepts définis au niveau du modèle
de données.
Ceci afin de pouvoir représenter les propriétés des données.
Ce niveau de représentation n’est pas nécessairement lié
à la représentation interne sous forme de fichiers. Il regroupe
en général la définition de types spécifiques
et la définition de règles de cohérence.
Rendre transparent le partage des données entre différents
utilisateurs.
Ceci signifie que plusieurs utilisateurs doivent pouvoir utiliser la base
de façon concurrente et transparente. Le problème posé
ici est du au fait que le SGBD pour des raisons évidentes de performances
(partage du CPU) doit permettre des exécutions concurrentes sur une
même base de données.
Assurer la confidentialité des données.
Il est nécessaire de pouvoir spécifier qui à le droit
d’accéder ou de modifier tout ou partie d’une base de données.
Il faut donc se prémunir contre les manipulations illicites qu’elles
soient intentionnelles ou accidentelles. Cela nécessite d’une part
une identification des utilisateurs, la constitution de groupes d’utilisateurs
avec des recouvrements potentiels et d'autre part, une spécification
des droits ajout, suppression, mise à jour). Il est évident
que garantir la confidentialité des données engendre un surcoût
en temps au niveau des manipulations.
Assurer le respect des règles de cohérence
définies sur les données.
A priori, après chaque modification sur la base de données,
toutes les règles de cohérence doivent être vérifiées
sur toutes les données. Evidemment, une telle approche est irréalisable
pour des raisons de performances et il faut déterminer des moyens de
trouver précisément quelles règles et quelles données
sont susceptibles d’être concernées par les traitements réalisés
sur la base de données. Ces traitements doivent pouvoir être
effectués sans arrêter le système.
Fournir différents langages d'accès selon
le profil de l’utilisateur.
En général, on admet que le SGBD doit au moins supporter un
langage adressant les concepts du modèle. Dans le cas du modèle
relationnel, ce langage est le langage SQL. Néanmoins ce type de langage
ne permet pas tous les types de manipulation et les SGBD proposent soit un
langage plus complet au sens Turing du terme avec la possibilité de
définir des accès à la base de données, soit un
couplage d’un langage tel que SQL avec un langage de programmation conventionnel
(tels que le langage C ou le langage Cobol). La définition d’une interface
entre une base de données et le Web pose ce type de problème
de spécification et de navigation dans une base de données.
Etre résistant aux pannes.
Ceci afin de protéger les données contre tout incident matériel
ou logiciel qu’il soit intentionnel ou fortuit. Il faut donc garantir la cohérence
de l’information et des traitements en cas de panne. Les applications opérant
sur des bases de données sont souvent par nature amenées à
opérer des traitements longs sur d’importants volumes de données.
Les possibilités de panne en cours de traitement sont donc nombreuses
et il faut fournir des mécanisme de reprise en cas de panne.
Posséder une capacité de stockage élevée.
Permettre ainsi la gestion de données pouvant atteindre plusieurs milliards
d’octets. Les capacités de stockage des ordinateurs sont en augmentation
croissante. Cependant, les besoins des utilisateurs sont également
en croissance forte. Avec l’essor des données multimédia (texte,
image, son, vidéo) les besoins sont encore accrus. Les unités
de stockage sont passées du mégaoctet (10^6) au gigaoctet
(10^9), puis au téra-octet (10^12), peta-octet
(10^16), et l'on commence à parler de exa-octet (10^18)
voire de zettaoctet (10^21).
Pouvoir répondre à des requêtes avec
un niveau de performances adapté.
Une requête est une recherche d’information à effectuer sur une
ou plusieurs bases de données qui peut impliquer des caractéristiques
descriptives sur l’information ou des relations entre les données.
La puissance des ordinateurs n’est pas la seule réponse possible à
apporter aux problèmes de performance. Une requête peut généralement
être décomposée en opérations élémentaires.
L’ordre d’exécution des opérations en fonction de leurs propriétés
(associativité, commutativité) ainsi que le regroupement de
certaines opérations utilisant le même ensemble de données
sont des éléments qui permettent de diminuer significativement
le temps d’exécution d’une requête.
Fournir des facilités pour la gestion des méta-données.
Par exemple à travers un dictionnaire de données ou un catalogue
système. Les méta-données concernent les données
sur le schéma de la base de données (relations, attributs, contraintes,
vues), sur les données (vues), sur les utilisateurs (identification,
droits) et sur le système (statistiques). Ces données doivent
être gérées et consultées de la même manière
que les données afférent à l’application. Cette notion
de catalogue assure également une certaine flexibilité au niveau
de l'utilisation du SGBD. Cette flexibilité permettant l’ajout sous
contrôle de nouveaux utilisateurs ainsi que la modification de structures
de données existantes sous certaines conditions. De plus, ce type d’information
permet entre autre à l’administrateur de la base de données
ou au SGBD lui-même d’adapter la politique de stockage en fonction du
contenu.
Il existe des SGBD de complexité variable qui possèdent tout
ou partie des propriétés ci-dessus. Prenons en exemple deux produits
assez caractéristiques : le SGBD relationnel Oracle 7 et le SGBD
relationnel Access. Le SGBD Oracle 7 est un SGBD relationnel utilisé
pour des applications critiques et qui offre un maximum des caractéristiques
présentées ici. Le SGBD Access est un SGBD dans le monde de l’informatique
individuelle qui présente l’avantage d’une grande facilité d’utilisation
et qui peut convenir à des application de taille réduite ou moyenne.
L’aspect convivial de ce dernier étant évident. En revanche, les
niveaux de performance et de sécurité ne sont pas comparables.
Architecture de SGBD
Les SGBD reposent sur trois niveaux d’abstraction
qui assurent l’indépendance logique et physique des données, autorisent
la manipulation de données, garantissent l’intégrité des
données et optimisent l’accès aux données. L’architecture
ANSI/SPARC
spécifie cette architecture à trois niveaux pour un
SGBD :
Le niveau externe.
Il regroupe toutes les possibilités d’accès aux données
par les différents usagers. Ces accès, éventuellement
distants, peuvent se faire via différents types d’interfaces et langages
plus ou moins élaborés. Ce niveau détermine le schéma
externe qui contient les vues des utilisateurs sur la base de données
c’est à dire le sous-ensemble de données accessibles ainsi que
certains assemblages d’information et éventuellement des informations
calculées. Il peut donc exister plusieurs schémas externes représentant
différentes vues sur la base de données avec des possibilités
de recouvrement.
Le niveau conceptuel.
Il correspond à la vision des données générale
indépendante des applications individuelles et de la façon dont
les données sont stockées. Cette représentation est en
adéquation avec le modèle de données utilisé.
Dans le cas des SGBD relationnels, il s’agit d’une vision tabulaire où
la sémantique de l’information est exprimée en utilisant les
concepts de relation, attributs et de contraintes d’intégrité.
Le niveau conceptuel est défini au travers du schéma conceptuel.
Le niveau physique.
Il regroupe les services de gestion de la mémoire secondaire. Il s’appuie
sur un système de gestion de fichiers pour définir la politique
de stockage ainsi que le placement des données. Cette politique est
définie en fonction des volumes de données traitées,
des relations sémantiques entre les données ainsi qu’en fonction
de l’environnement matériel disponible. Comme le suggère la
figure 1ci-dessous, il est tout à fait possible de répartir
les données sur différents supports de stockages distribués
sur un réseau. Le niveau physique est donc responsable du choix de
l’organisation physique des fichiers ainsi que de l’utilisation de telle ou
telle méthode d’accès en fonction de la requête. Ce niveau
doit également assurer le partage des ressources, la gestion de la
concurrence et des pannes. La personne responsable de ce niveau est un administrateur
de bases de données. Son rôle est à la fois d’assurer
la mise en place et le contrôle des procédures systèmes
liées à la gestion de la base mais aussi de gérer les
droits d’accès à la base.
Cette architecture vise à identifier différents niveaux de structuration
dans un SGBD comme cela est illustré sur la figure 1. L’objectif visé
par cette structuration est l’obtention d’une indépendance maximale entre
les niveaux.
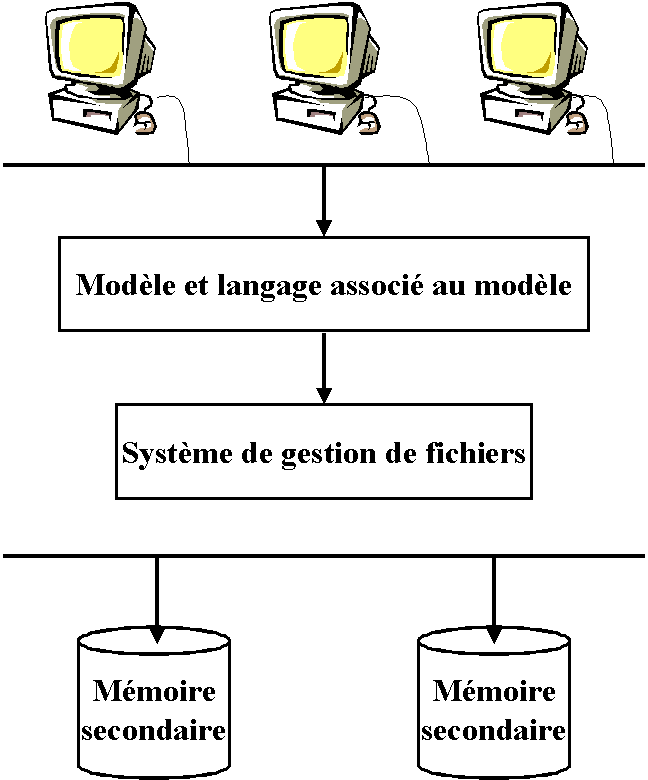
Figure 1 : architecture d’un SGBD
Notions d'indépendance
Indépendance logique.
Possibilité de modifier le schéma conceptuel sans remettre en
cause les schémas externes ou les programmes d’application. L’ajout
de nouveaux concepts ne doit pas modifier des éléments qui n’y
font pas explicitement référence.
Indépendance physique.
Possibilité de modifier le schéma physique et la politique de
stockage (modification de l’organisation physique des fichiers, ajout ou suppression
de méthodes d’accès) sans remettre en cause le schéma
conceptuel et donc le schéma externe. Le but de ce niveau d’indépendance
est de rendre transparente la gestion physique des données aux programmes
d’application.
Cette architecture logique permet donc d’identifier la logique de structuration
d’un système de gestion de bases de données. D’un point de vue
fonctionnelle, il est possible d’identifier plusieurs composants que l’on retrouve
dans la plupart des SGBD. La figure 2 illustre cette composition.
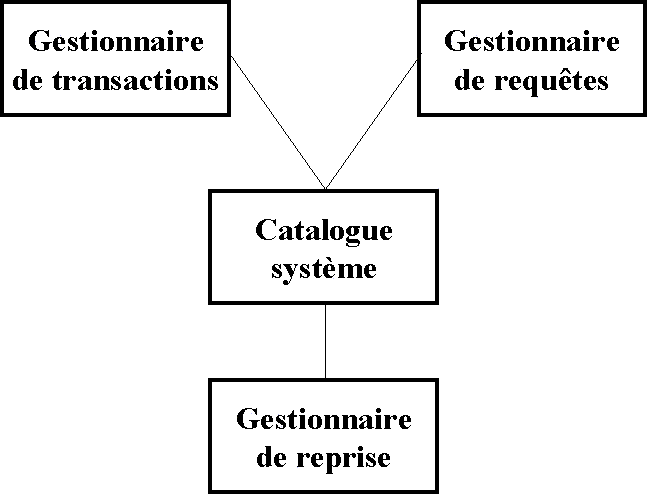
Figure 2 : composants d’un SGBD
Le catalogue système ou dictionnaire de données
est un composant au coeur de la communication entre les autres composants. Il
contient toutes les méta-données utiles au système. Ces
méta-données correspondent à la description des données
(type, taille, valeurs autorisées, etc.), aux autorisations d’accès,
aux vues et autres éléments systèmes. Le catalogue correspond
à la réalisation de l’architecture à trois niveaux décrite
précédemment. Le catalogue contient la description des différents
schémas (physique, conceptuel et externes) ainsi que les règles
de passage d’un schéma vers l’autre.
Le gestionnaire de requêtes est responsable du
traitement des commandes des utilisateurs visant à stocker, rechercher
et mettre à jour des données dans la base de données. En
utilisant les informations stockées dans le catalogue, il interprète
ces requêtes et les traduit en des requêtes d’accès physique
aux données susceptibles d’être traitées par le système
de gestion de fichiers.
Le gestionnaire de transactions est responsable de
traiter les transactions. Une transaction est un ensemble d’opérations
d’accès et de mise à jour de données émises par
un utilisateur. Ces opérations doivent être traitées comme
un tout et le gestionnaire de transaction doit assurer d’une part l’indivisibilité
des opérations soumises, la cohérence du système après
l’exécution de l’ensemble des opérations, l’isolation des traitements
par rapports aux autres traitements qui peuvent être soumis de façon
concurrente et enfin la persistance des résultats une fois l’ensemble
des opérations achevées.
Le gestionnaire de reprise est un élément
essentiel d’un SGBD qui doit remplacer le système de gestion de fichier
traditionnel afin de minimiser les effets d’une panne sur la base de données.
Un tel système ne peut évidemment pas être sûr ou
sécurisé à 100 %. Néanmoins, il est indispensable
que le gestionnaire de reprise puisse pallier à certaines pannes qui
peuvent avoir différentes causes telle qu’une division par zéro
dans un programme, à un problème de disque défectueux ou
à une panne d’alimentation. L’objectif essentiel du gestionnaire de reprise
est de restaurer la base de données dans un état cohérent.
Vue les causes très différentes de panne et les difficultés
liées à cette gestion, cet élément est un élément
central qui concerne environ 10 % ou plus du code d’un SGBD.
